I want a way for end users to add fields to my Django app without programming. I’ll publish this eventually, but here how to implement it. Latest version is now at http://code.google.com/p/django-custom-field/

First I made 2 models. One for the field and one for the values associated with the field.
from django.contrib.contenttypes.models import ContentType
from django.db import models
class CustomField(models.Model):
"""
A field abstract -- it describe what the field is. There are one of these
for each custom field the user configures.
"""
name = models.CharField(max_length=75)
content_type = models.ForeignKey(ContentType)
field_type = models.CharField(max_length=1, choices=(('t','Text'),('i','Integer'),('b','Boolean (checkbox)'),), default='t')
def get_value_for_object(self,obj):
return CustomFieldValue.objects.get_or_create(field=self,object_id=obj.id)[0]
def __unicode__(self):
return unicode(self.name)
class Meta:
unique_together = ('name','content_type')
class CustomFieldValue(models.Model):
"""
A field instance -- contains the actual data. There are many of these, for
each value that corresponds to a CustomField for a given model.
"""
field = models.ForeignKey(CustomField, related_name='instance')
value = models.CharField(max_length=255,blank=True,null=True)
object_id = models.PositiveIntegerField()
#content_type = models.ForeignKey(ContentType)
def __unicode__(self):
return unicode(self.value)
Next I wanted this to work with admin. So I extend any ModelAdmin you want with this I need. Notice we don’t handle errors! I have my 3 simple data types all do client side validation, then if the server validation comes up invalid, it just throws them away. It’s less than ideal but I wasn’t sure how to get it to display the errors correctly.
from django import forms
from django.contrib.contenttypes.models import ContentType
from django.contrib import admin
from django.forms.widgets import TextInput
from models import *
class NumberInput(TextInput):
input_type = 'number'
class CustomFieldAdmin(admin.ModelAdmin):
def __create_custom_form(self, obj_id=None):
custom_fields = CustomField.objects.filter(content_type=ContentType.objects.get_for_model(self.model))
custom_form = forms.Form(prefix="cstm")
for field in custom_fields:
if field.field_type == 'i':
custom_form.fields[field.name] = forms.IntegerField(label=field.name, required=False, widget=NumberInput(attrs={'style':'text-align:right;','step':1}))
elif field.field_type == 'b':
custom_form.fields[field.name] = forms.BooleanField(label=field.name, required=False)
else:
custom_form.fields[field.name] = forms.CharField(label=field.name, max_length=255, required=False)
if obj_id:
value = CustomFieldValue.objects.get_or_create(field=field,object_id=obj_id)[0]
custom_form.fields[field.name].initial = value
return custom_form
def render_change_form(self, request, context, *args, **kwargs):
context['custom_form'] = self.__create_custom_form(context['original'].id)
return super(CustomFieldAdmin, self).render_change_form(request, context, *args, **kwargs)
def save_model(self, request, obj, form, change):
custom_form = self.__create_custom_form()
custom_form.data = request.POST
custom_form.is_bound = True
if custom_form.is_valid():
data = custom_form.cleaned_data
for key,data_field in data.items():
custom_field = CustomField.objects.get_or_create(content_type=ContentType.objects.get_for_model(self.model), name=key)[0]
custom_value = CustomFieldValue.objects.get_or_create(field=custom_field,object_id=obj.id)[0]
custom_value.value = data_field
custom_value.save()
# Hope that client side validation works since we don't handle errors here!
return super(CustomFieldAdmin, self).save_model(request, obj, form, change)
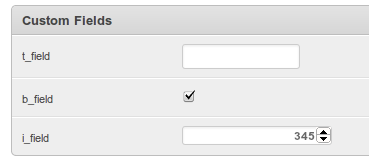
Now we have to edit the admin template. This isn’t ideal but I couldn’t think of any other way. Edit change_form.html and add
{% include "admin/includes/custom_field_fieldset.html" with custom_form=custom_form %}
wherever you want. I say it’s not ideal because if you make lots of customizations it’s hard to keep track. Blocks help with this, BUT Django’s admin content block is pretty big, and I wanted to add mine basically in the middle of the content. Now you need the referenced custom_field_fieldset.html
{% spaceless %}
{% if custom_form.fields %}
<fieldset class="module">
<h2 class="collapse-handler">Custom Fields</h2>
{% for field in custom_form %}
{{ field.label_tag }}
{{ field }}
</div>
{% endfor %}
</fieldset>
{% endif %}
{% endspaceless %}
That’s it. So now for the real test, can I add a custom field to my custom field model?

Now you can customize your fields while you customize fields! If you need to access the custom fields programmatically you can make shortcuts like
def get_custom_fields(self):
return CustomField.objects.filter(content_type=ContentType.objects.get_for_model(Whatever))
Next I need to add integration with my applications import tool, make something so you can extend Model to get that helper function, and integrate with django-admin-export. Maybe even create a dropdown field_type which would require another model to store the data in. Then I promise to post to pypi.